
HuggingFace 今日 Trending | GSPO 助力 Qwen3、AI 短片生成、双曲空间检索等 11 篇论文速览
今日 HuggingFace trending 前 11 篇论文一次看完:Qwen3 背后的强化学习算法 GSPO、让大模型少想却更准的 MUR、从文字生成完整短片的 Captain Cinema、百亿参数国产大模型 TeleChat2/T1 开源,以及视觉 Transformer、地球 3D 建模、词向量、视频检索等多个方向。通俗解读,外行也能看懂。
リサーチノート
今日收录 HuggingFace 当前 trending 前 11 篇论文,覆盖强化学习训练算法、推理效率、视频生成、图像生成、视觉模型架构、3D 地球建模、视频检索、人脸识别等方向。
1. GSPO:让 Qwen3 变强的那个强化学习算法
论文:Group Sequence Policy Optimization 1
Qwen3 发布后不少人好奇它用了什么训练技巧。这篇来自阿里的论文把答案说清楚了:一个叫 GSPO 的强化学习算法。
现在训练大模型用 RL(强化学习)已经是标配。主流方案 GRPO 的逻辑是:生成一批回答,按 token(词元)级别来衡量「新策略」和「旧策略」的偏差,再做截断式更新。问题是,token 级别的重要性比值(importance ratio)会积累偏差,训练起来不够稳定,尤其是 MoE(混合专家)这类大模型更容易出问题。
GSPO 改了一件事:把「衡量偏差」的粒度从 token 级 换成 整段序列级。直觉上,一个回答好不好,是整段话的整体质量决定的,不是某几个词。这样一来,截断和奖励都在序列层面做,训练更稳定,效率也更高。
论文中阿里团队报告:GSPO 在训练 Qwen3(含 MoE 版本)时比 GRPO 更稳、性能更好,还简化了 RL 训练基础设施的设计复杂度。
状态:预印本。
2. MUR:让大模型「想少一点」但做题还更准
论文:MUR: Momentum Uncertainty guided Reasoning for Large Language Models 2
大模型推理时会「过度思考」——明明一道题不需要那么多步骤,模型还是把算力全耗光了。这篇论文想解决这件事,且不需要重新训练模型。
方法叫 MUR,核心思路借用了物理学里的动量概念:让模型在推理时追踪每一步的「不确定度」,并用类似动量的累积方式平滑历史不确定度。遇到「这步拿不准」的时候多想,遇到「这步稳」的时候少想。同时提供一个叫
gamma-control 的单参数旋钮,直接调整整体推理预算。在 MATH-500、AIME24、AIME25、GPQA-diamond 四个测试集上,用 Qwen3 1.7B/4B/8B 模型测试,MUR 平均减少 50% 以上的计算量,同时准确率还提升了 0.62–3.37 个百分点。
状态:预印本。
3. Captain Cinema:从文字描述直接生成短片
论文:Captain Cinema: Towards Short Movie Generation 3
「给段文字描述,生成一部完整短片」——这在之前大多停留在概念层面。这篇论文提出了一个叫 Captain Cinema 的框架,专门处理多场景、有叙事逻辑的短视频生成。
它的思路是两步走:
- 自上而下规划关键帧:先根据剧情描述生成一批关键帧图片,作为全片的叙事骨架。这一步保证场景、角色在全片里视觉上是连贯的。
- 自下而上合成视频:以关键帧为条件,用支持长上下文的视频合成模型填充关键帧之间的时空动态。
底层用了专为长视频数据设计的 MM-DiT(多模态扩散 Transformer)交叉训练策略,并在定制的电影场景数据集上训练。
项目主页:thecinema.ai
状态:预印本。
4. TTS-VAR:让图像自回归模型「生成时也能再想想」
论文:TTS-VAR: A Test-Time Scaling Framework for Visual Auto-Regressive Models 4
Test-Time Scaling(推理时扩展计算)在语言模型上已经证明有效,这篇论文把它搬到了视觉生成模型上——具体是针对 VAR(视觉自回归模型)。
VAR 生成图片的方式类似「从粗到细的分层猜测」:先定大概轮廓(粗尺度),再逐步填细节(精细尺度)。TTS-VAR 把这个过程建模为「路径搜索问题」:
- 粗尺度阶段:生成的 token 质量评估困难,用聚类多样性搜索保留结构上有差异的候选路径,避免一开始就错方向。
- 精细尺度阶段:用基于重采样的潜力筛选,依据包含历史生成信息的 potential score 选出最有希望的候选。
同时引入自适应降序批大小调度,在生成过程中动态平衡计算量和探索空间。
在 Infinity 模型上,GenEval 得分从 0.69 提升到 0.75,相对提升 8.7%。代码已开源:TTS-VAR GitHub
状态:预印本。
5. EarthCrafter:用 AI 建出真实比例的地球表面
论文:EarthCrafter: Scalable 3D Earth Generation via Dual Sparse Latent Diffusion 5
现有 3D 生成方法能做一个物体、一个房间,但地理尺度的生成(几千平方公里)几乎没人做成过。这篇论文从两方面同时发力:
数据侧:发布了 Aerial-Earth3D,目前最大的 3D 航拍数据集,50,000 个场景,每个 600m×600m 采自美国本土,共 4,500 万张多视角 Google Earth 图像,带深度图、法线图、语义分割和相机位姿。
模型侧:提出 EarthCrafter,架构上将结构生成(几何)和纹理生成(外观)分开:
- 双稀疏 3D-VAE 分别压缩几何体素和纹理 2D Gaussian Splats 到紧凑隐空间,降低大地理尺度的计算代价。
- 条件自适应的流匹配模型支持语义图、图像、无条件三种混合输入,几何和纹理可以独立生成。
支持城市布局语义引导生成、无条件地形合成等多种下游应用。项目主页:EarthCrafter
状态:预印本。
6. TeleChat2/T1:115B 国产大模型正式开源
论文:Technical Report of TeleChat2, TeleChat2.5 and T1 6
中国电信旗下的 TeleChat 系列发了一份技术报告,介绍三个新版本:TeleChat2、TeleChat2.5 和 T1。
三款模型架构没有太大变化,增益来自训练策略:
- TeleChat2:在 10 万亿 token 高质量数据上预训练,再经 SFT(监督微调)和 DPO(直接偏好优化)。
- TeleChat2.5:在 TeleChat2 基础上加入特定领域持续预训练 + 强化学习,优化代码生成和数学推理,特点是推理速度快。
- T1:同样走强化学习路线,专注复杂推理,支持长链式思维(CoT),在数学和编程上有显著提升。报告称 T1-115B 在部分基准上超过 OpenAI 的 o1-mini 和 GPT-4o。
两款旗舰型号(T1-115B 和 TeleChat2.5-115B)均已开源,提供 35B 和 115B 两个规模。
状态:预印本(技术报告)。
7. GloVe 2024:十年后的老朋友换新装
论文:A New Pair of GloVes 7
GloVe(Global Vectors for Word Representation)是 2014 年斯坦福发布的词向量经典模型,在 Transformer 时代之前影响了无数 NLP 项目。十年过去,语言在变、世界在变,原来的词向量对很多新词无能为力。
这篇论文训练了 2024 版 GloVe,用 Wikipedia、Gigaword 以及 Dolma 数据集的子集。评测维度覆盖词汇量比较、类比测试、命名实体识别(NER)。结果显示:
- 新词(近十年涌现的文化、社会、技术词汇)覆盖率明显提升。
- 类比和相似度等结构性任务上表现与 2014 版相当。
- 在时效性依赖较强的 NER 数据集(如非西方新闻报道数据)上有明显提升。
对于仍在用静态词向量的轻量级 NLP 任务来说,这批新模型值得替换。
状态:预印本。
8. SpelkeNet:让视觉模型像婴儿一样理解「什么是一件东西」
论文:Discovering and using Spelke segments 8
人类婴儿很早就知道「一个杯子」是一个整体——不是靠语义标签,而是靠「它们一起动」这个物理信号。发展心理学把这类知觉单位叫 Spelke 物体(以认知科学家 Elizabeth Spelke 命名)。
现有的视觉分割(比如 SAM)靠的是语义范畴,分类依赖人工定义。这篇论文问的是:能不能用「运动因果关系」来定义物体边界?
SpelkeNet 是一个预测运动分布的视觉世界模型。给定一个图像,它预测:(1)如果「戳」这里,哪些区域会动(运动可能性图);(2)整个场景会怎么反应(期望位移图)。通过模拟大量虚拟戳触(statistical counterfactual probing),把相关运动统计聚合成 Spelke 分割区。
在新发布的 SpelkeBench 数据集上,SpelkeNet 超过了 SAM 等有监督基线。在 3DEditBench(物理对象操控)上,当 SpelkeNet 分割作为输入时,各类现成操控模型性能均有提升。
状态:预印本。
9. Iwin Transformer:不需要位置编码的视觉 Transformer
论文:Iwin Transformer: Hierarchical Vision Transformer using Interleaved Windows 9
Swin Transformer 是当前主流视觉骨干之一,但它有个缺陷:局部窗口注意力每次只看一小块,要靠连续两个 Block 才能近似「看全图」。Iwin Transformer 想在单个模块内就实现全局信息流动。
方法是交叉窗口注意力 + 深度可分离卷积的组合:注意力机制连接远距离 token,卷积连接相邻 token,两者合并在同一个 Iwin 模块里。这样单模块就能全局感知,不再需要两个 Block 的接力。
同时,Iwin 去掉了位置编码,使模型可以直接在不同分辨率上微调,无需重新插值位置编码。
实验结果:ImageNet-1K 分类 87.4% Top-1 准确率,语义分割和视频动作识别上也有竞争力表现。代码已开源:Iwin-Transformer GitHub
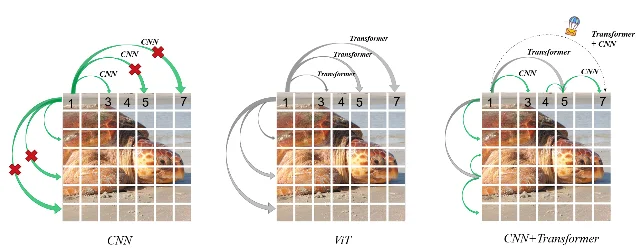
图:Iwin Transformer 架构示意,来自论文页。
状态:预印本。
10. HLFormer:用双曲空间找更好的视频片段
论文:HLFormer: Enhancing Partially Relevant Video Retrieval with Hyperbolic Learning 10
搜索长视频时经常遇到的问题:输入一段文字,视频里只有其中某几分钟是相关的,其余部分无关——这叫「部分相关视频检索」(PRVR)。
现有方法在欧氏空间里做向量匹配,但视频的时序层级结构(某片段属于某场景属于某主题)本质上是树状的,欧氏空间表达树结构效率不高。
HLFormer 引入双曲空间(Hyperbolic Space)来处理这个层级问题:
- 把 Lorentz 注意力块和 Euclidean 注意力块结合,在两种空间里同时编码视频特征。
- 用「均值引导自适应交互模块」动态融合两种空间的特征。
- 设计「偏序保持损失」(Partial Order Preservation Loss),在 Lorentz 圆锥约束下强制「文本嵌入 < 视频嵌入」的语义层级。
在标准 PRVR 基准上超过了现有最优方法。代码已开源:HLFormer GitHub(ICCV 2025 接收)。
状态:已接收 ICCV 2025。
11. 人脸年龄性别识别:广告定向投放的老问题新做法
论文:Deep Learning-Based Age Estimation and Gender Classification for Targeted Advertisement 11
这篇论文提出用定制 CNN 同时完成年龄估计和性别分类,用于广告定向投放场景。创新点是:将两个任务的信息在网络里共享——年龄和性别在人脸特征里高度相关,分开训练会浪费这种关联。
实验数据:性别分类准确率 95%,年龄估计平均绝对误差 5.77 岁。论文也点出了明显短板:对青少年年龄段的估计误差偏大,需要针对性数据增强。
这类双任务人脸模型在商业场景里应用广泛,但部署时的隐私问题(用户未明确同意的情况下推断年龄性别)在论文中没有讨论。
作者机构未披露,审稿状态:预印本,且为单人/小团队投稿,同行评审状态未知。
このコンテンツについて、さらに観点や背景を補足しましょう。