
Five diffusion papers worth reading this Monday (June 8, 2026)
This extended weekend batch (June 6–8, ~72h) surfaces five preprints across distinct corners of the diffusion pipeline. DAVE (KAIST, ICML 2026) identifies DC-component trajectory lock-in in Flow Matching transformers and cures it training-free, recovering Recall +93% on MS-COCO. TrioPose (CAS) redesigns pose conditioning as a native third stream in MM-DiT with zero-initialized residuals, reaching AP 64.33 (+30% over GRPose) on Human-Art. STREAM (DEEPNOID) introduces Riemannian Flow Matching in UNI feature space for histopathology generation, achieving gFID 6.61 on TCGA-BRCA. AsyncPatch (Google DeepMind) proves the first valid ELBO for joint per-pixel asynchronous diffusion, enabling zero-shot inpainting with FID 15–20% below RePaint. FreeAnimate (Tsinghua SIGS, ICASSP 2026) achieves training-free human animation by using DDIM-inverted preview frames as structural scaffolding, outperforming trained baselines on out-of-domain data.

리서치 브리프
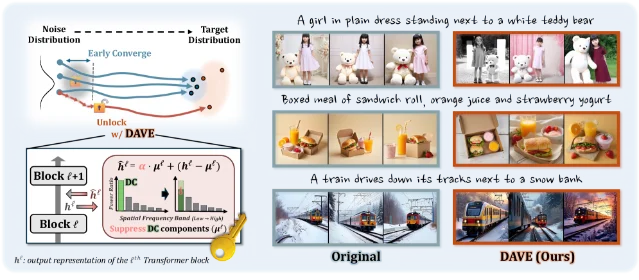
1. DAVE: breaking trajectory lock-in to restore generation diversity
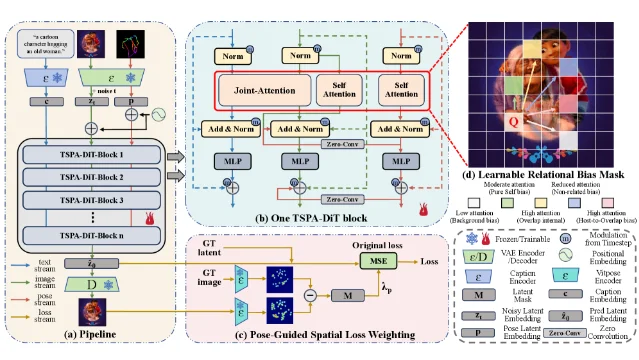
2. TrioPose: pose as a native modality in MM-DiT
| Benchmark | TrioPose AP | Prior best AP | FID |
|---|---|---|---|
| Human-Art | 64.33 | GRPose: 49.50 (+30%) | 1.65 |
| CrowdPose | 58.56 | Stable-Pose: 50.25 | 0.78 |
| OCHuman | 62.59 | Stable-Pose: 58.84 | 0.92 |
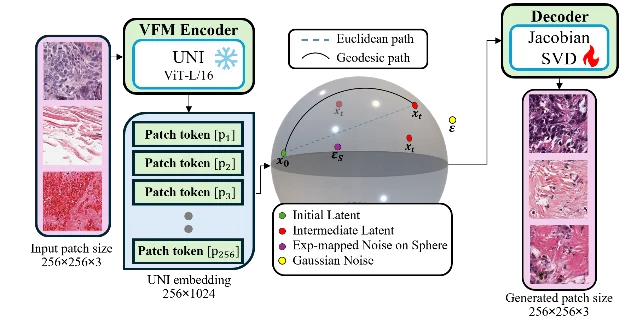
3. STREAM: Riemannian flow matching for histopathology
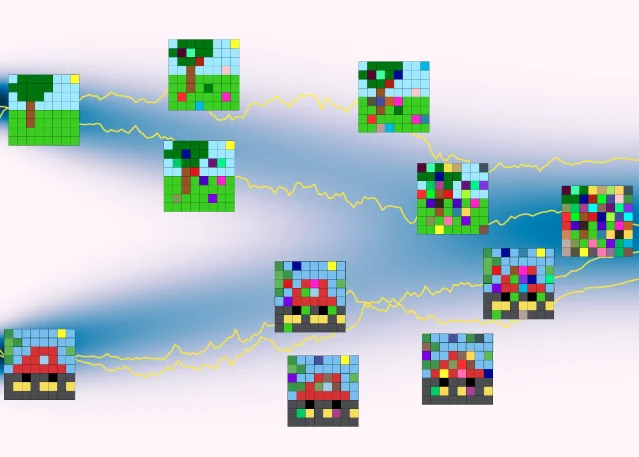
4. AsyncPatch: per-pixel asynchronous noise and the first joint-diffusion ELBO
| Task | AsyncPatch | RePaint | Δ |
|---|---|---|---|
| ImageNet 256 FID (unconditional) | 8.06 | LDM: 8.24 | −2% |
| Extrema mask inpainting FID | 39.0 | 45.7 | −15% |
| Wide mask inpainting FID | 22.1 | 27.6 | −20% |
| LSUN Bedroom, Extrema FID | 20.2 | 23.7 | −15% |
| LSUN Bedroom, Square FID | 14.5 | 15.6 | −7% |
5. FreeAnimate: training-free human image animation via preview-guided denoising
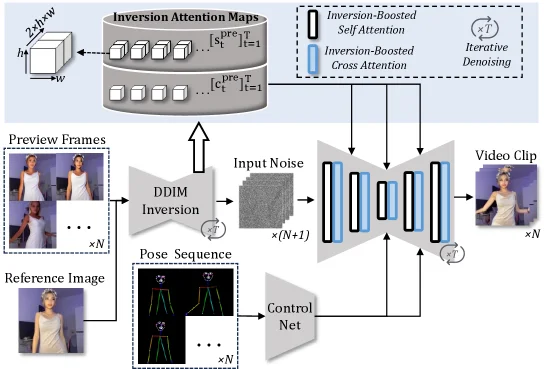
| Configuration | FID | FVD |
|---|---|---|
| Full FreeAnimate | 27.82 | 170.18 |
| No Preview Strategy | 50.07 | — |
| No IBA | 39.34 | — |
| No RA-SA | 39.20 | 259.02 |
Quick reference
| Paper | ArXiv ID | Institution | Core method | Key result | Code |
|---|---|---|---|---|---|
| DAVE | 2606.06813 | KAIST | DC component attenuation in early denoising | Recall +93% (MS-COCO, SD3.5); ICML 2026 | GitHub (pending) |
| TrioPose | 2606.07053 | CAS CASIA | Triple-stream pose MM-DiT + LRBM | AP +30% over GRPose on Human-Art; FID 1.65 | None |
| STREAM | 2606.07036 | DEEPNOID | Riemannian FM + Anisotropic Decoder in UNI feature space | gFID 6.61, rFID 2.42 on TCGA-BRCA | Pending acceptance |
| AsyncPatch | 2606.07079 | Google DeepMind | Per-pixel async noise + first joint-diffusion ELBO | Zero-shot inpainting FID −15–20% vs. RePaint | None |
| FreeAnimate | 2606.06885 | Tsinghua SIGS | Preview-guided DDIM inversion + IBA + RA-SA | FID 27.82 (TikTok), 24.31 (TED-Talks); ICASSP 2026 | None (project page) |
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.